Plant
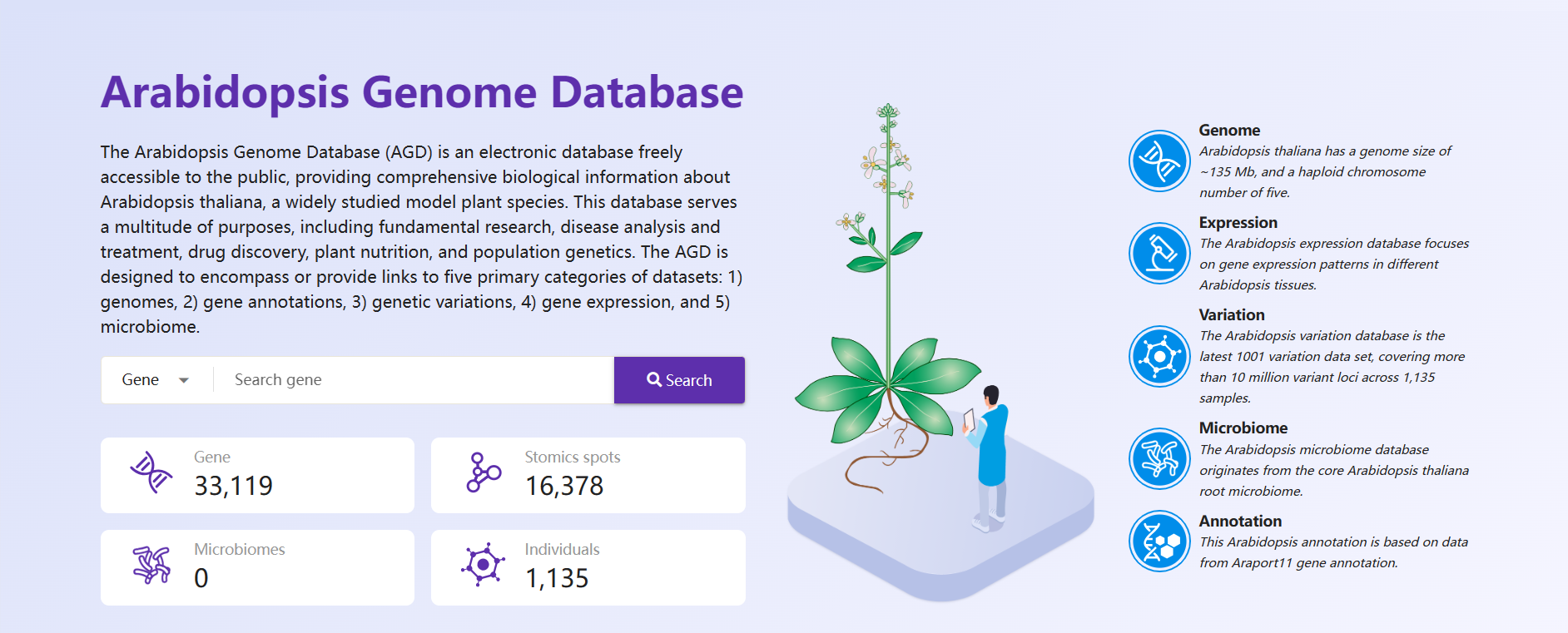
The Arabidopsis Genome Database (AGD) is an electronic database freely accessible to the public, providing comprehensive biological information about Arabidopsis thaliana, a widely studied model plant species. This database serves a multitude of purposes, including fundamental research, disease analysis and treatment, drug discovery, plant nutrition, and population genetics. The AGD is designed to encompass or provide links to five primary categories of datasets: 1) genomes, 2) gene annotations, 3) genetic variations, 4) gene expression, and 5) microbiome.
LettuceDB serves as a portal to multi-omics data for cultivated lettuce and its wild relatives,aims to provide help for lettuce research and breeding.The data on this website were generated as a collaborative projects between BGI-Research, China National Gene Bank (CNGB),CGN, Huazhong Agricultural University and other research institutes. Data and information released on this website are provided on an "as is" basis.
Wei, T., Van Treuren, R., Liu, X., Zhang, Z., Chen, J., Liu, Y., ... & Liu, H. (2021). Whole-genome resequencing of 445 Lactuca accessions reveals the domestication history of cultivated lettuce. Nature Genetics, 53(5), 752-760.
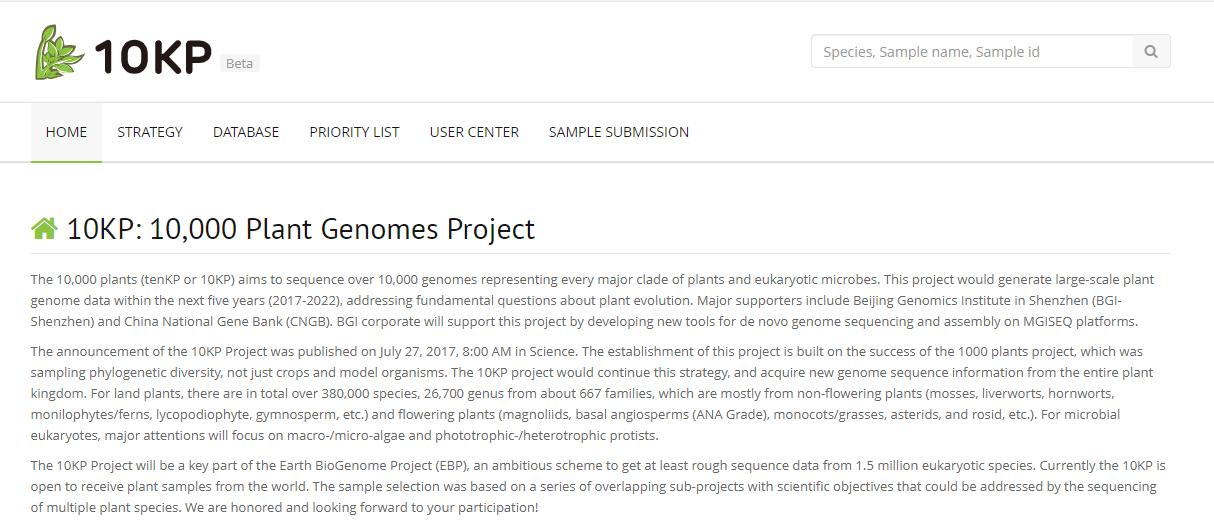
The 10,000 plants (tenKP or 10KP) aims to sequence over 10,000 genomes representing every major clade of plants and eukaryotic microbes. This project would generate large-scale plant genome data within the next five years (2017-2022), addressing fundamental questions about plant evolution. Major supporters include Beijing Genomics Institute in Shenzhen (BGI-Shenzhen) and China National Gene Bank (CNGB). BGI corporate will support this project by developing new tools for de novo genome sequencing and assembly on MGISEQ platforms.
Cheng, S., Melkonian, M., Smith, S. A., Brockington, S., Archibald, J. M., Delaux, P. M., ... & Wong, G. K. S. (2018). 10KP: A phylodiverse genome sequencing plan. Gigascience, 7(3), giy013.
The millet database is based on the data of the millet genome project researched by BGI and Zhangjiakou Academy of Agricultural sciences. The database records the genotype-phenotype information of millet. Users can query and retrieve the genotype of millet through the phenotype, and the corresponding phenotype can be retrieved by genotype. Besides, the database also applies the big data technology and machine learning method to construct the genotype-phenotype model to promote the intelligent molecular breeding.
Jia, G., Huang, X., Zhi, H., Zhao, Y., Zhao, Q., Li, W., ... & Han, B. (2013). A haplotype map of genomic variations and genome-wide association studies of agronomic traits in foxtail millet (Setaria italica). Nature genetics, 45(8), 957-961.
ZEAMAP is a comprehensive database incorporating population level multi-omic data for the Zea genus, including genomics, transcriptomics, genetic variants, phenotypes, metabolomics, epigenetics, and genetic mapping loci of complex traits. ZEAMAP is user friendly, with the ability to interactively integrate, visualize, and cross-reference multiple different omics datasets. The database is powered by the National Key Laboratory of Crop Genetic Improvement (Huazhong Agricultural University), Beijing Genomics Institute-Shenzhen (BGI)and China National GeneBank(CNGB), and aims to support the maize improvement by integrating pan Zea multi-omics information.
Gui, S., Yang, L., Li, J., Luo, J., Xu, X., Yuan, J., ... & Yan, J. (2020). ZEAMAP, a comprehensive database adapted to the maize multi-omics era. IScience, 23(6).

The Brassica Database (BRAD) is a database which includes not only newly released genome sequences of Brassiceae species, but also published genomic data of most other Brassicaceae species.
Wang, X., Wu, J., Liang, J., Cheng, F., & Wang, X. (2015). Brassica database (BRAD) version 2.0: integrating and mining Brassicaceae species genomic resources. Database, 2015, bav093.
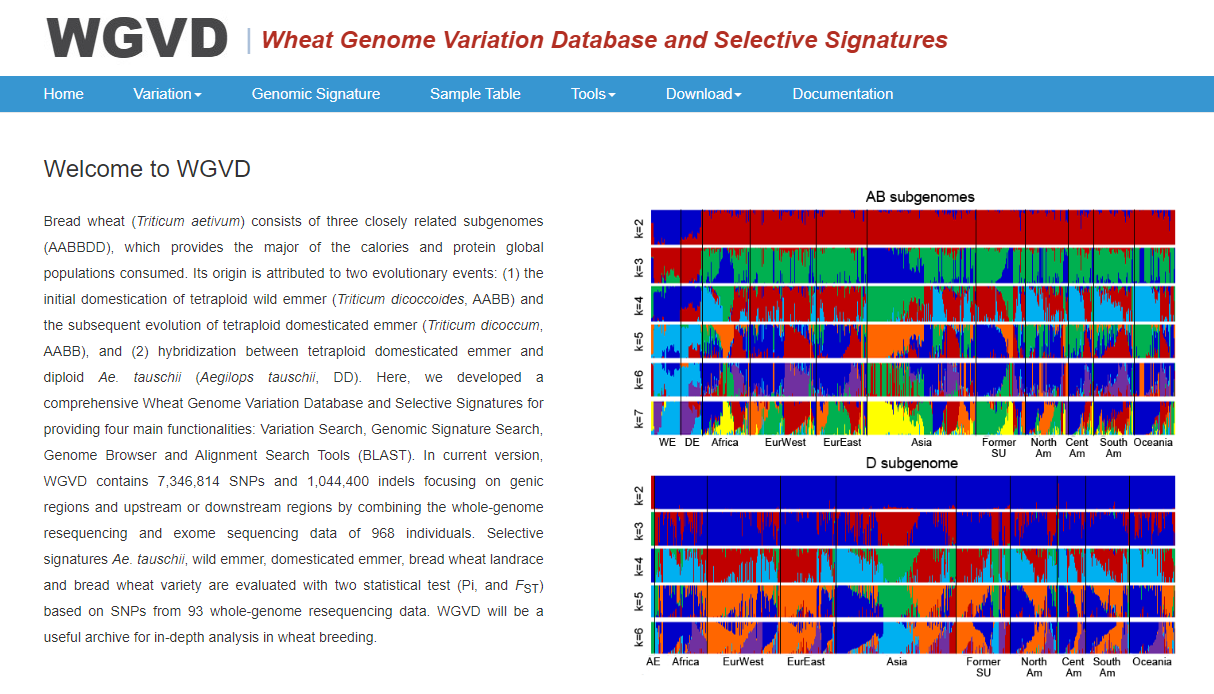
The Northwest Agriculture and Forestry University Wheat Variation Database is deployed as a mirror database in CNGBdb. It contains data for resequencing and exon sequencing of 968 wheat germplasm. Variations include 7,353,314 SNPs and 1,044,400 indels, and provides statistics of wheat population selection signals. (Pi and FST) and display.
Avni, R., Nave, M., Barad, O., Baruch, K., Twardziok, S. O., Gundlach, H., ... & Distelfeld, A. (2017). Wild emmer genome architecture and diversity elucidate wheat evolution and domestication. Science, 357(6346), 93-97.
The Database of 10,000 Medicinal Plants is designed based on the data of Guangxi Innovation-Driven Development Special Project, Construction of Big Data Centre of Medicinal Plants (Guike AA18242040). The database aims at building the largest big data center of medicinal plants in the world, interpreting the relationship between the big data of medicinal plants and the pharmaceutical efficacy, and, via smart innovation of medicinal plant resources and smart creation of medicinal plant products, implementing sustainable utilization of medicinal plant resources and accomplishing resource digitization, data industrialization as well as industry modernization, so as to promote the development of traditional Chinese medicine and the health industry.

The germplasm resources of medicinal plants, as the source of the traditional Chinese medicine industry, play an important role in the development of Chinese medicine. In recent years, the research on medicinal plant resources has developed rapidly, which has provided huge new drug creation resources for the pharmaceutical industry, and research on gene resources of medicinal plants has gradually become a hot topic in the industry. As one of the countries with the most abundant germplasm resources of medicinal plants in the world, strengthening the conservation, sustainable use and research of medicinal plant genetic resources is of great significance to the development of Chinese medicine industry.
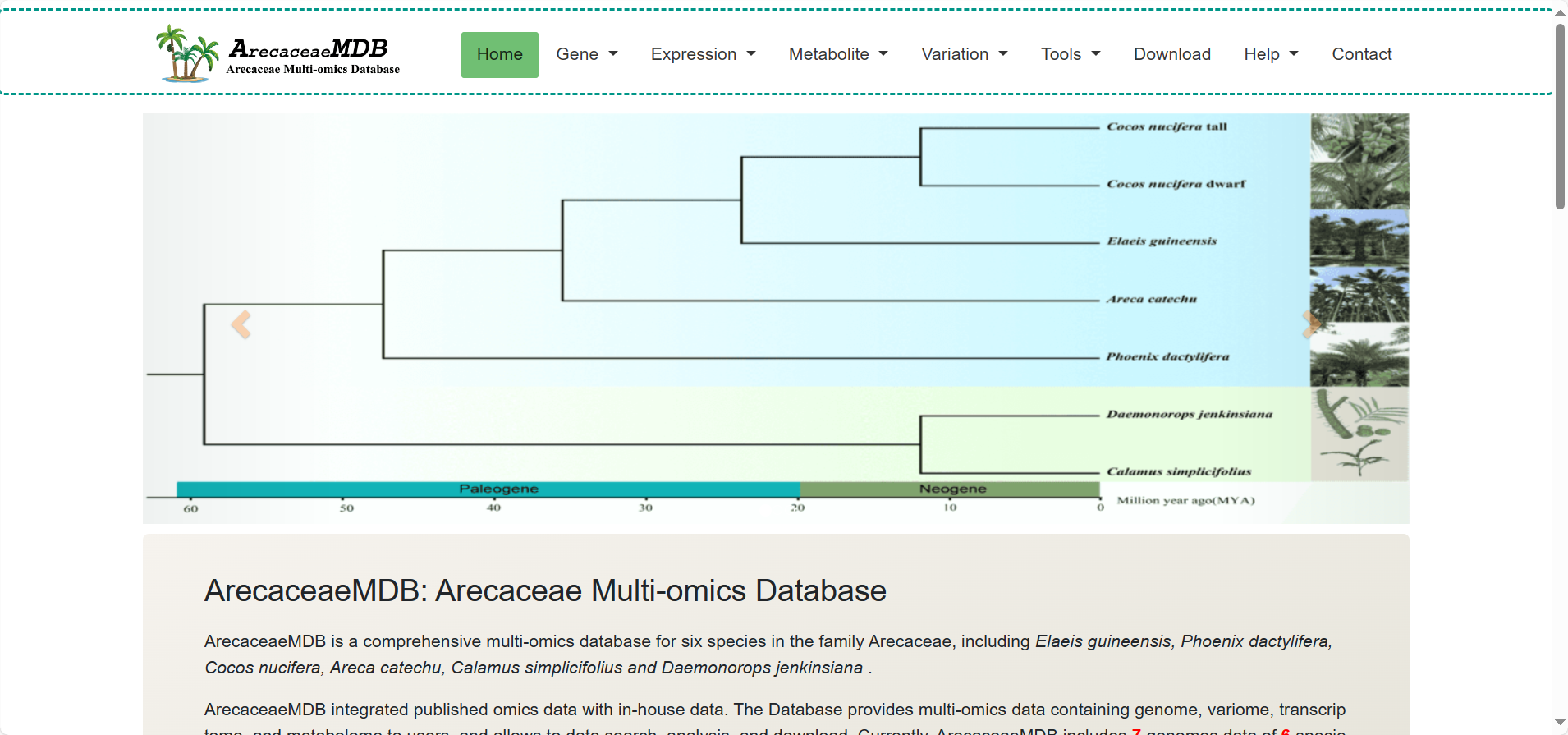
ArecaceaeMDB is a comprehensive multi-omics database for six species in the family Arecaceae, including Elaeis guineensis, Phoenix dactylifera, Cocos nucifera, Areca catechu, Calamus simplicifolius and Daemonorops jenkinsiana .ArecaceaeMDB integrated published omics data with in-house data. The Database provides multi-omics data containing genome, variome, transcriptome, and metabolome to users, and allows to data search, analysis, and download.
The Nelumbo Genome Database is constructed by collaboration between the Wuhan Institute of Landscape Architecture and Research Group of Aquatic Plant Biogeography from Wuhan Botanical Garden, Chinese Academy of Sciences. This database not only can browse and retrieve multiple sets of data but also perform simple analysis based on deployed tools such as Blast and Primer.
Li, H., Yang, X., Wang, Q., Chen, J., & Shi, T. (2021). Distinct methylome patterns contribute to ecotypic differentiation in the growth of the storage organ of a flowering plant (sacred lotus). Molecular ecology, 30(12), 2831-2845.
Animal
The Bird 10,000 Genomes (B10K) Project plans to generate representative draft genome sequences from all extant bird species within the next five years (2015-2020). The B10K project will complete a genomic level tree of the entire bird species, decode the relationship between genetic variation and phenotypic variation, uncover the correlation of genetic evolutionary and biogeographical and biodiversity patterns, evaluate the impact of various ecological factors and human influence on species evolution, and unveil the demographic history.
Zhang, G. (2015). Bird sequencing project takes off. Nature, 522(7554), 34-34.
FishT1K (Transcriptomes of 1,000 fishes) project was officially launched by BGI in November 2013, with the aim of generating genome-wide transcriptome sequences for 1,000 diverse species of fishes using RNA-seq. The FishT1K database will establish the first data storage, application, sharing platform for fish group research, greatly advancing the study of fish biology, eventually contributing towards global fish biodiversity conservation efforts and sustainable utilization of natural resources. In addition, the database will promote development of new technologies and softwares for transcriptome sequencing, data analysis, annotation, and storage.
Sun, Y., Huang, Y., Li, X., Baldwin, C. C., Zhou, Z., Yan, Z., ... & Shi, Q. (2016). Fish-T1K (Transcriptomes of 1,000 Fishes) Project: large-scale transcriptome data for fish evolution studies. Gigascience, 5(1), s13742-016.
Fish10K (The 10,000 Fish Genomes Project) was officially launched by BGI at ICG-Ocean 2019, which was held in September 2019, aiming to sample, sequence, assemble and analyze 10,000 representative fish genomes under a systematic context within ten years. We will construct high-quality reference genomes for representative species in all orders (Phase I) and families (Phase II) in concert with the generation of draft genome sequences for additional related species (Phase III).
Fan, G., Song, Y., Yang, L., Huang, X., Zhang, S., Zhang, M., ... & He, S. (2020). Initial data release and announcement of the 10,000 Fish Genomes Project (Fish10K). GigaScience, 9(8), giaa080.
Insects are one of the most species-rich groups of metazoan organisms. They play a pivotal role in most non-marine ecosystems and many insect species are of enormous economical and medical importance. Unraveling the evolution of insects is essential for understanding how life in terrestrial and limnic environments evolved. The 1KITE (1K Insect Transcriptome Evolution) project aims to study the transcriptomes (that is the entirety of expressed genes) of more than 1,000 insect species encompassing all recognized insect orders.
Misof, B., Liu, S., Meusemann, K., Peters, R. S., Donath, A., Mayer, C., ... & Zhou, X. (2014). Phylogenomics resolves the timing and pattern of insect evolution. Science, 346(6210), 763-767.
MicroOrganism

The Microbiome Database (MDB) provides relevant sample and microbial data. The Human Microbial Database currently covers sequencing data volume of 83G and phenotypic information from 1,443 cases of stool samples from 8 human intestinal microbiological research projects. It also contains the most complete human intestinal microbial gene set in the world.
The "Million Microbiomes from Humans Project" (MMHP) was officially launched at the 14th International Conference on Genomics (ICG-14). Scientists from China, Sweden, Denmark, France, and Latvia agreed to collaborate on a large-scale microbial metagenomic project, aiming to sequence and analyze one million samples from the intestine, mouth, skin, reproductive tract, and other organs in the next three to five years to construct a microbiome map of the human body and build the world's largest database of the human microbiome.
The completion of the QTP Animal Microbiome Project has generated more than 30Tb of gut microbial metagenomics data. Combined with other omics tools such as culturomics, metabolomics, and function verifications based on germ-free animal models, this project not only provides new knowledges for understanding omics mechanism of those animals' adaptations to extreme environments, but also offers an opportunity and guarantee for the mining, protection and sustainable utilization of unique gut microbial species and genetic resources.
The Database of Deep-Sea Life (Deepseadb) involves both sequencing resource and metadata of ecological communities, isolates and animals collected from the deep-sea (>1000m depth). This database aims to be a dictionary for the exploration and utilization of genetic resources in the deep-sea, which provides uniformed metadata, standard analyzed data and batched analysis tool.