"Insights into extensive microbial protein diversity among varied deep-sea ecosystems"
Zongan Wang, Yang Guo, Lele Wang, Denghui Li, Fei Guo et al. (Under review)
Summary
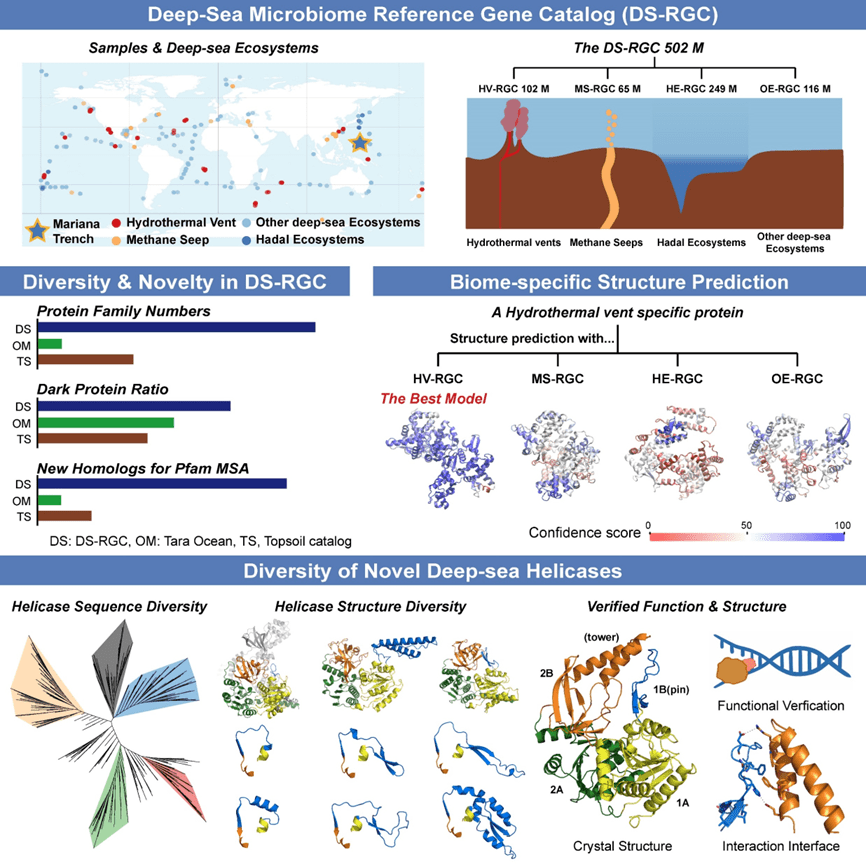
The various hostile environments in the deep sea (≥ 1000 m) shape high biodiversity. However, how proteins diversified among deep-sea ecosystems is not fully understood. Here, 2138 deep-sea metagenomes are integrated into a comprehensive Deep-Sea microbial Reference Gene Catalog (DS-RGC), encoding 502 million non-redundant proteins which are mainly functionally unknown. The DS-RGC exhibits enormous protein uniqueness and diversity, supplementing considerable new unique homologs to an order of magnitude more Pfam families than other ecosystem-wide catalogs, which leads to improved accuracy and high efficiency for deep-sea protein structure prediction. In addition, we discovered over 8,000 distinct novel superfamily 1 (SF1) helicases from DS-RGC with sequence and structural diversity related to different deep-sea ecosystems, in which active enzymes with novel motif features were verified. Thus, this study considerably enhances our understanding of deep-sea biodiversity and serves as an invaluable resource for studies in the relevant fields.
Graphic Abstract
Datasets
| Filename | Description | Size | MD5 | Download | |
|---|---|---|---|---|---|
| DS-RGC.fa.gz | The complete catalog | 52.6 GB | e089f81c9eaad9233cce4415d44b32f3 | ||
| HV-RGC.fa.gz | The subsets of the DS-RGC | 10.5 GB | 8f9a5dc10da78f2b786d476e5a5262b9 | ||
| MS-RGC.fa.gz | The subsets of the DS-RGC | 6.36 GB | 72b2a247df0ccc729853f7dd0c2d65ba | ||
| HE-RGC.fa.gz | The subsets of the DS-RGC | 29.1 GB | 0741a0ff9880519707bf21c7d0c11b1e | ||
| OE-RGC.fa.gz | The subsets of the DS-RGC | 11.4 GB | 69a5c6f256f819dca09df0b478a35d98 | ||
| DS-RGC-ecosystem.tsv.gz | The ecosystem sources of each protein sequences | 1.21 GB | b60fce0f34f220292d65fb6dd5ca7f59 | ||
| DS-RGC-taxonomy.tsv.gz | The taxonomy annotations | 1.77 GB | cf184f3b82df6d895e28b9a78e2f0b2d | ||
| DS-RGC-eggNOG.tsv.gz | The eggNOG annotations | 18.8 GB | 4fa4386238999441e0d5459091ce4ebf | ||
| DS-RGC-KEGG.tsv.gz | The KEGG orthologous group annotations | 6.32 GB | d02c540d32ffadcaabedff6a57788671 |
Methods
Sample collection and Sequencing
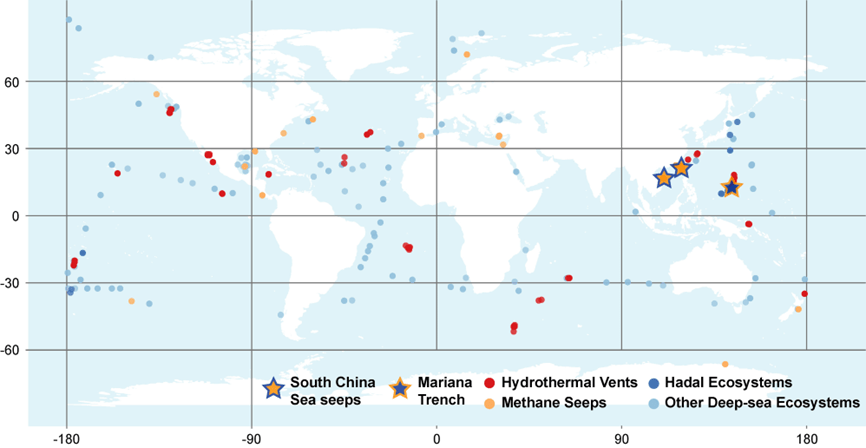
Published deep-sea metagenomic sequencing data were obtained from NCBI. In detail, we employed the NCBI E-utilities tool to acquire the metadata of 884 deep-sea samples, which were collected in the ocean area deeper than 1000 m and sequenced with metagenomic pair-end libraries. Then we assigned the 884 samples into four ecosystem groups based on sampling information, including hydrothermal vents, methane seeps, hadal ecosystems, and other deep-sea ecosystems (Table 1). In addition, we collected 60 cold seep samples from the South China Sea and 1194 sediment samples from the Mariana Trench in addition (Table 1), and these samples were sequenced on the BGISEQ-2000/DNBSEQ-T1 platforms.
Construction of the Deep-sea Microbial Gene Reference Catalog (DS-RGC)
All the raw reads were quality controlled using Fastp (v0.23.1) with default parameters to remove low-quality, adapter contaminated and duplicated reads. The filtered reads were assembled with MEGAHIT (v1.2.9) with the parameter of --presets meta-sensitive. For the 1254 newly sequenced samples in this study, contigs shorter than 1000 bp were removed from the assemblies, and considering the low sequencing depth of the 884 published datasets, the threshold for contig filtering was extended to 500 bp. According to the assembly results, MetaGeneMark (v3.38) was used to predict coding sequences (CDSs) in the assembled contigs longer than 100 bp, and the CDSs were translated into protein sequences. In total 1895.94 million protein-coding genes were obtained, and we determined the completeness of genes based on the presence of both start and stop codon. All protein sequences were clustered with MMseqs2 with the following options: --min-seq-id 0.95 -c 0.90 --cov-mode 1 --cluster-mode 3, resulting in a nonredundant microbial gene catalog (the DS-RGC) comprising 502 M protein coding genes.
Contributors
Zongan Wang#, Yang Guo#,*, Lele Wang#, Denghui Li#, Fei Guo#, Ziyu Zhao, Zhenjun Liu, Liang Meng, Weijia Zhang, Weishu Zhao, Inge Seim, Aijun Jiang, Tao Yang, Zidong Su, Li Zhou, Nannan Zhang, Qianyue Ji, Xiaoyi Po, Chaodi Kong, Junyi Chen, Liuxin Shi, Yue Zheng, Huan Zhang, Yinzhao Wang, Mo Han, Weiwen Wang, Jiayu Chen, Fangfang Jiang, Qian Cen, Jun Wang, Guohai Hu, Guoqiang Mai, Linlin Luo, Yue Liu, Haixin Chen, Tao Zeng, Xiaofeng Wei, Xiang Xiao, Jian Wang, Huanming Yang, Bo Wang, Liqun Chen, Wenwei Zhang, Ying Gu, Xun Xu*, Yuxiang Li*, Shanshan Liu*, Yuliang Dong*
Acknowledgements
We appreciate all the assistance provided by the crews on RV Tansuoyihao and Kexue. We thank the staff scientists at beamline BL18U1 of the Shanghai Synchrotron Radiation Facility for providing technical support and assistance in data collection. We also appreciate the technical support from CNGBdb for library construction and sequencing.